Foreword From 2021
A while ago, I listened to an amazing podcast episode about DynamoDB decided to do one of AWS’s DynamoDB hands-on tutorials and create a little presentation about what I learned to share at a meetup.
Enjoy!
Objectives
-
Get to know each other
-
Compare and contrast DynamoDB data modeling to relational data modeling
-
Describe the importance of partitioning in DynamoDB
Non-Work Facts About Me!
Chuck 
|
|
Notice and Wonder
What do you notice? |
What do you wonder? |
Notice and Wonder Debrief

NoSQL vs. Relational Data Modeling — Online Gaming
Think of an online multiplayer game.
What are some "entities" involved? |
What are some access patterns? |
The Relational Way
Suppose we want to query for all the usernames of users in a particular game.
| Star Schema | Pros | Cons |
|---|---|---|
|
|
|
The DynamoDB Way
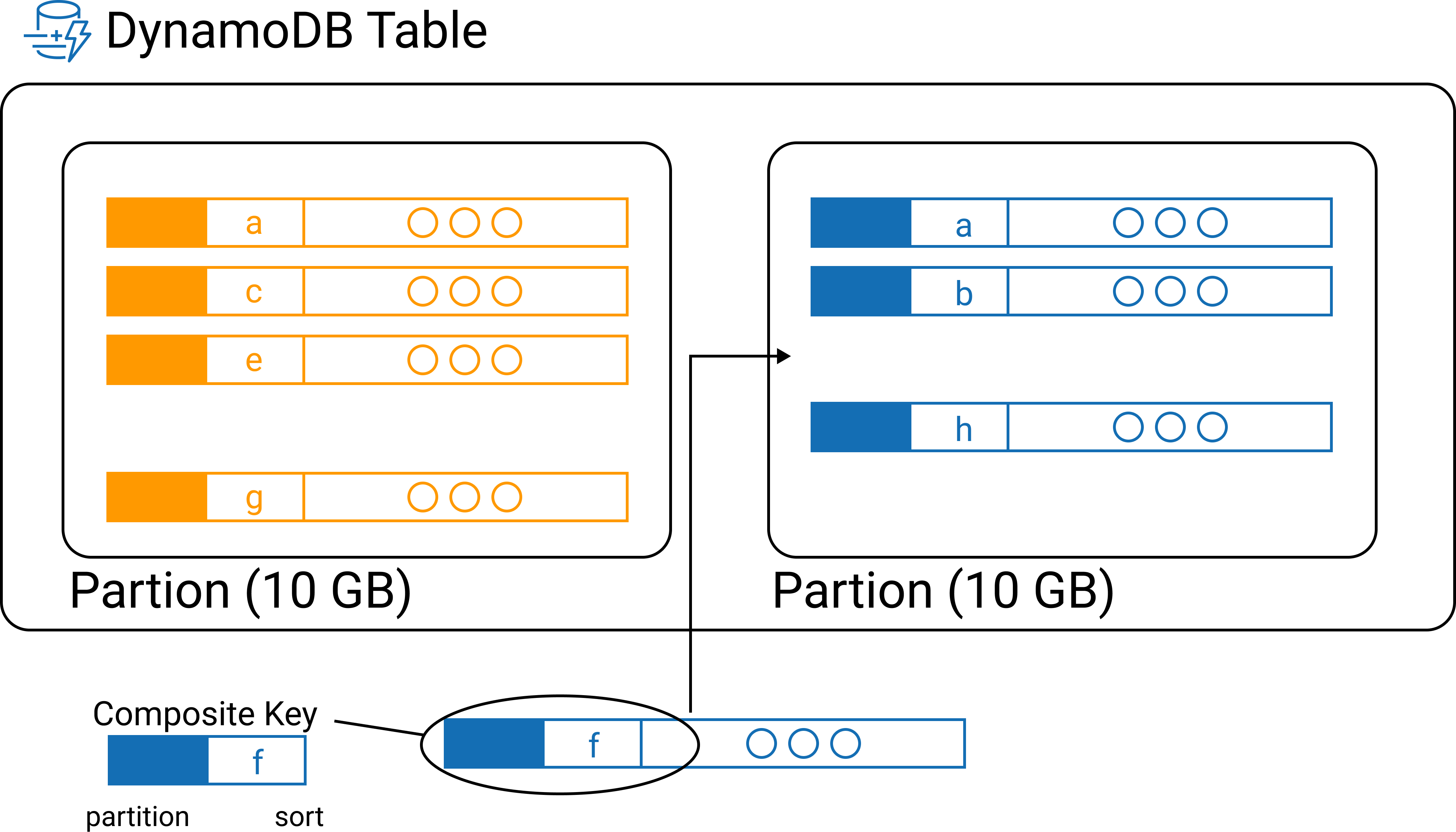
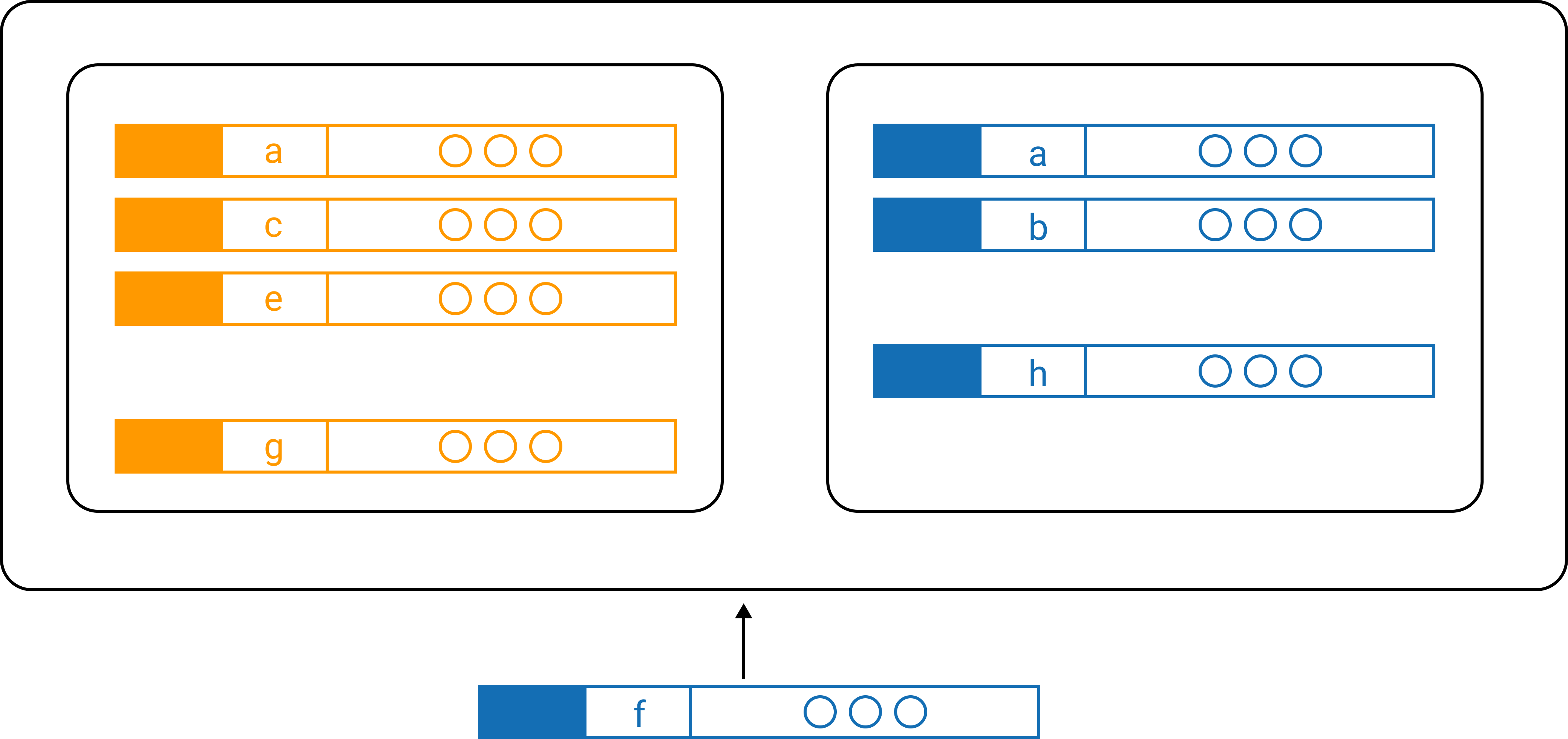
This is all one big, hyper-scalable table! It looks like two entity tables and a join table, but really it’s one big table where the entities and join are created by clever design of the primary and sort keys, which we’ll see in the next slide.
|
Note
|
One table with O(1) lookup by primary key, or O(log(n)) if including a sort key. No joins! You plan the access pattern into your data model and include everything in one table. |
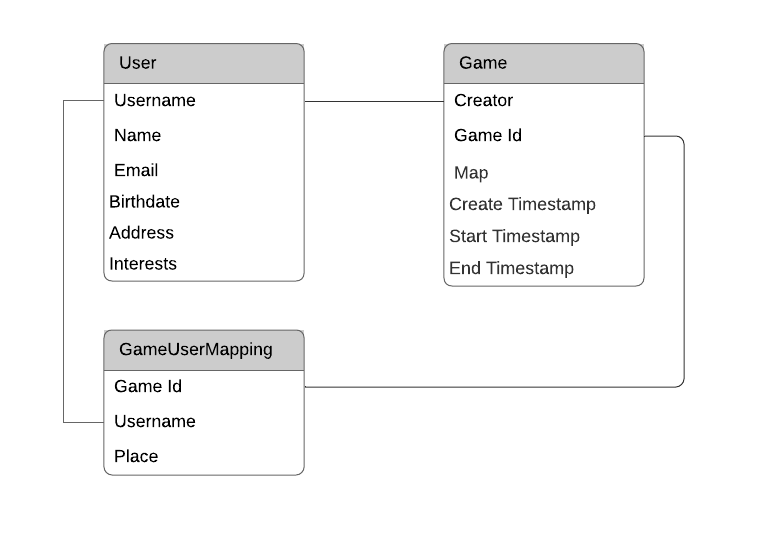
Design the Primary Key
| Entity | Partition Key (a.k.a. HASH) | Sort Key (a.k.a. RANGE) |
|---|---|---|
User |
|
|
Game |
|
|
UserGameMapping |
|
|
Code Example
Query multiple entities in one request to one table!
Take a moment to think about what this query does:
game_id = input("what game ID do you want to look up?")
resp = dynamodb.query(
TableName='battle-royale',
KeyConditionExpression="PK = :pk AND SK BETWEEN :placeholder AND :users",
ExpressionAttributeValues={
":pk": { "S": "GAME#{}".format(game_id) },
":placeholder": { "S": "#PLACEHOLDER#{}".format(game_id) },
":users": { "S": "USER$" },
},
ScanIndexForward=True
)sample response
This query takes a given game ID and looks up all the users in that game. Let’s say the game ID is abc123. The PK part of the KeyConditionExpression stands for "Primary Key", which is the key used to determine which DynamoDB partition holds the data.
Now that we have found the partition where game ID abc123 lives, the next step is to use the sort key, SK, to grab all the users. We look up records in order from :placeholder to :users, which are further specified in the ExpressionAttributeValues parameter. The :placeholder expression corresponds to the string #PLACEHOLDER#abc123 (type denoted by S). The expression :users corresponds to the string USER$.
The # symbol is 35 in ascii, and $ is 36, so USER$ is greater than all USER#<USERNAME> entries. That means this query will return the game followed by all the users in that game in ascending order by username. For example:
{"GAME#abc123" : "#PLACEHOLDER#abc123"}
{"GAME#abc123": "USER#myuser1"}
{"GAME#abc123": "USER#myuser2"}
{"GAME#abc123": "USER#myuser3"}
...Next Step: Secondary Indexes
Secondary indexes are very useful in DynamoDB. They allow you to query data by attributes other than the primary key. This opens up more access patterns. The benefits of secondary indexes come at the cost ($ literally $) of more reads and writes as DynamoDB automatically updates indexes. It is easy to use secondary indexes poorly, so I encourage you to dig into the tutorial in the reference to learn more about best practices with secondary indexes. Namely:
-
Sparse secondary index
-
Create an index that filters down to a specific subset that won’t grow indefinitely
-
example: create index to find all open games on a specific map
-
-
Inverted index
-
Switch the roles of primary key and sort key
-
example: find all games a user has played (opposite of what we did earlier when we found all users in a specific game)
-
3, 2, 1 Reflection
-
What are 3 things you learned?
-
What are 2 things you found interesting?
-
What’s 1 question you still have?
Objectives
-
Get to know each other
-
Describe the importance of partitioning in DynamoDB
-
Compare and contrast DynamoDB data modeling to relational data modeling