Sunpower Stats
I have a MySunPower system, and I love looking at my data. However, the app is not as flexible a I want it to be. It only lets you see a graph of energy usage/production between two points in time. But I want to answer questions like “how has my usage/production been trending in the month of February over the last several years” or “what is the distribution of usage/production for the hour of 4-5pm” or “how does the last 4 months of usage compare to the same period the previous year”.
Well, here’s the result!
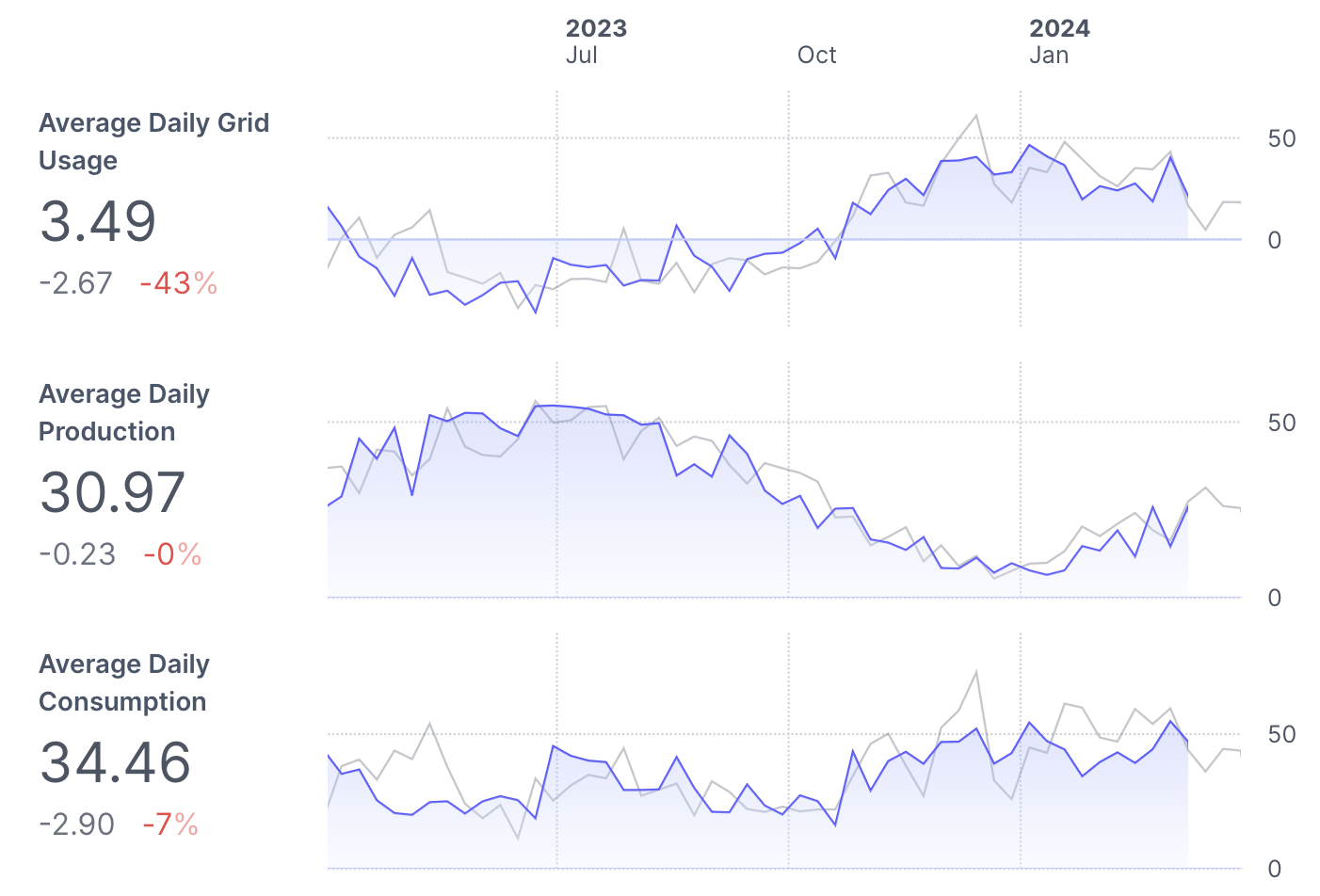
Go to the GitHub repo to see:
- Python functions for interacting with the MySunPower GraphQL API to download data locally
- documentation to interact with data locally via
duckdb - Rill Data dashboards to visualize the data
Download Data
Get Access Token
As of writing, I am unsure how to programmatically get the “site key” and access token. Sunpower uses an OAuth2 flow to generate a JSON Web Token (jwt) but I’m not exactly sure how it is implemented.
Instead, here is how to get the site key and access token manually:
- Navigate to https://login.mysunpower.com/login/login.htm and log in.
- Open up the developer tools (
Develop -> Show Web Inspectorin Safari) - Open the
Networktab in the web inspector and click the trash can to start fresh. - Go back a day to load yesterday’s Sunpower data.
- Inspect the
graphqlrequestAuthorizationheader. It saysBearer <token>. - Take that token and put it in a file called
.env - Inspect the request itself to find the
siteKeyand also put that value in.env.
token="<your long token here>"
site_key="<your site key here>"
The token lasts a pretty long time, so this is probably sufficient.
Environment setup
Set up a Python virtual environment and install requirements.
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
Run the Download
Modify the timestamps in get_timeseries_csv.py and run
python get_timeseries_csv.py
The file will be available at data/timeseries/sunpower_timeseries.csv.
Get Fresh Data
Whenever you want, you can adjust the timestamps in get_timeseries_csv.py and csv filename and run it again to get a new csv with fresh data since the last import.
Then copy the data into the sunpower table in duckdb with
COPY sunpower FROM './data/timeseries/sunpower_<date>_to_<date>.csv' (HEADER);
Beware of duplicates! Make sure the timeseries don’t overlap.
Run SQL with duckdb
Create a duckdb Database
Install the duckdb CLI on your system. For Homebrew users, run
brew install duckdb
Create a database.
duckdb ./data/sunpower.db
Inside the duckdb shell, load the csv into a table.
CREATE TABLE sunpower (ts TIMESTAMP, consumption FLOAT, production FLOAT, grid FLOAT);
COPY sunpower FROM './data/timeseries/sunpower_timeseries.csv' (HEADER);
Create a few useful views.
create view sunpower_hourly as
select
ts,
year(ts) year,
month(ts) month,
day(ts) day,
production,
consumption,
grid
from sunpower;
create view sunpower_daily as
select
date_trunc('day', ts) day,
sum(production) as production,
sum(consumption) as consumption,
sum(grid) as grid
from sunpower
group by day;
create view sunpower_monthly as
select
date_trunc('month', ts) month,
sum(production) as production,
sum(consumption) as consumption,
sum(grid) as grid
from sunpower
group by month;
create view sunpower_yearly as
select
date_trunc('year', ts) year,
sum(production) as production,
sum(consumption) as consumption,
sum(grid) as grid
from sunpower
group by year;
Output these aggregates to csv if you’d like.
copy (select * from sunpower_daily) to './data/aggregates/daily.csv';
copy (select * from sunpower_monthly) to './data/aggregates/monthly.csv';
copy (select * from sunpower_yearly) to './data/aggregates/yearly.csv';
Play with duckdb
I thought this was interesting.
select
month(day) as month,
avg(production) production,
avg(consumption) consumption,
avg(grid) grid
from sunpower_daily
group by month
order by grid;
| month | production | consumption | grid |
|---|---|---|---|
| 6 | 48.59366670968011 | 24.173833327367902 | -24.419833369149515 |
| 7 | 51.70338710893186 | 36.753064496863274 | -14.950322639106982 |
| 8 | 44.24016130009606 | 29.734354813493066 | -14.505806475336994 |
| 5 | 44.31112911753477 | 31.381129051799014 | -12.930000026109479 |
| 9 | 36.298166707033914 | 24.128333315998315 | -12.169833363064875 |
| 4 | 38.02533335089684 | 33.15449992132684 | -4.870833339852592 |
| 10 | 27.655806478233107 | 26.446128989900313 | -1.2096774174020655 |
| 3 | 27.762253475414827 | 39.247746454368176 | 11.485492896498508 |
| 11 | 15.509166642930358 | 40.19949999178449 | 24.690333327340582 |
| 2 | 20.811058854530838 | 48.012352964983265 | 27.201294152920738 |
| 12 | 7.298552617112077 | 45.35565785024511 | 38.05710524291192 |
| 1 | 9.489139803154494 | 48.21580643823711 | 38.72666667590058 |
June is the most efficient month in terms of average daily net grid usage, sending ~10kWh more back to the grid each day than the next highest month. Production is high and consumption is low. These numbers indicate that most of the usage is seasonal, indicating heat/AC as the main usage.
What are other interesting questions to ask this data?
- Are there any trends when comparing the same month across years?
- What are the daily averages for each month across years?
- etc.
Exit duckdb
Press Ctrl+D at any time to exit the duckdb CLI shell. Enter again with duckdb data/sunpower.db.
Data Visualization with Rill
I followed the Rill Data quickstart to create a local dashboard.
In the UI, I chose duckdb source with this SQL:
select * from read_csv_auto('<path to>/sunpower/data/timeseries/sunpower_timeseries.csv', header = true);
Rill’s local environment apparently uses duckdb out of the box!
After you install the rill CLI, here is the command to start the UI server:
rill start sunpower-viz
And go to http://localhost:9009.
Rill also generated a dashboard using AI, which saved some time getting to a nice dashboard. For example, here is a year over year comparison of the month of January 2024 vs 2023 for total grid usage:
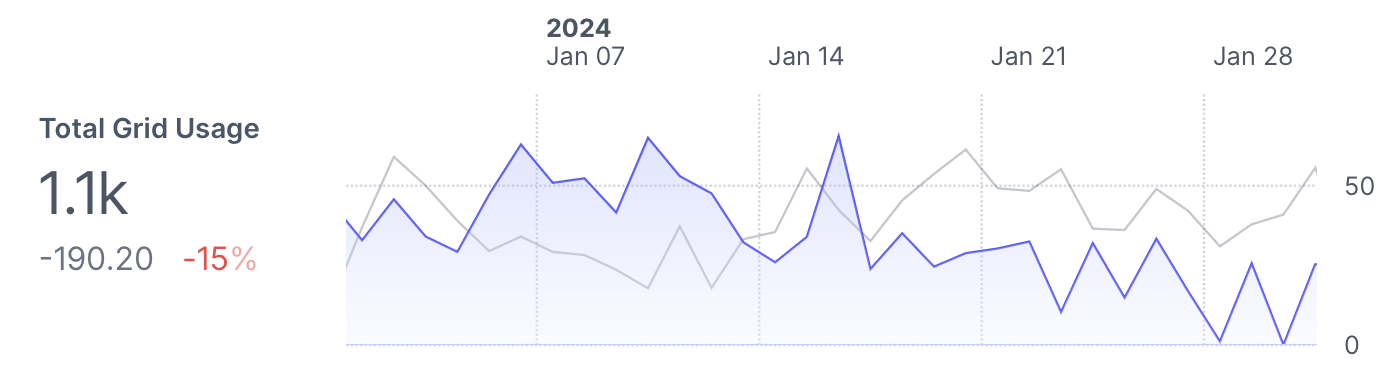
A 15% reduction in grid usage year over year!
Next Steps
- I’d love to hook up Apache Superset, Grafana, or some other data visualization tool to duckdb.
- Set up orchestrator job to load new data on a schedule (e.g. with Airflow or Prefect)
- Other ideas?
Real-Time with Materialize.
As an extension, I’ve thought about tapping into the server on my physical PVS6 box as outlined in this cool project to get real-time readings. I could then HTTP POST those readings directly into my Materialize database with the Webhook Source and maintain real-time views over the data.
Full disclosure: Materialize is my employer as of writing.